 By
·
3 minute read
By
·
3 minute read
For years, the phrase “💩 in, 💩 out” has been the go-to explanation for why bad data leads to bad outcomes. It’s a saying that reinforces a common fear: that your data is too messy, untrustworthy, or inaccurate to be useful. But what if the real problem isn’t the data itself, but rather a lack of trust in how that data is processed and understood?
The truth is, messy data is a myth. Every piece of data has value—the issue is whether you have the right technology to extract that value. With the right tools and partners, even the most unstructured, chaotic data can be cleaned, enriched, and transformed into a powerful asset.
What Does Messy Data Really Look Like?
The idea of messy data is often tied to data that is unorganized or incomplete. In practice, it can look like:
- Disorganized records: Data spread across multiple spreadsheets, with no consistent format.
- Unstructured data sources: PDFs, emails, or other documents that hold valuable information but are hard to extract.
- Incomplete or conflicting information: Data sets that don’t match up, leading to confusion and inaccuracies.
These challenges create friction for businesses, leading to missed opportunities and a lack of confidence in decision-making. But the real issue isn’t the data itself—it’s about how that data is being managed.
The Role of Technology in Cleaning and Structuring Data
Cleaning and structuring data is where the power of self-healing data modules and advanced data cleaning technologies come into play.
Traditional methods of data cleaning are reactive, requiring constant monitoring to identify issues and fix them manually. But with self-healing data modules, farms and suppliers can now rely on systems that automatically detect and correct inconsistencies (i.e. Manolin). This not only ensures that the data remains clean, but also optimizes it in real-time—without the need for continuous human intervention.
For example, extracting data from unstructured sources like PDFs is notoriously complex. Imagine trying to pull critical fish health records from a series of PDF reports that span years. Doing this manually would be overwhelming and error-prone. But with advanced data cleaning technologies, those PDFs can be parsed, structured, and integrated into a centralized system—transforming raw data into actionable insights.
The Need for Trust in Your Data and Technology Partners
The real barrier isn’t messy data—it’s a lack of trust in that data. When farms and suppliers don’t trust their data, they hesitate to rely on it for critical decisions. This leads to inefficiencies, costly mistakes, and missed opportunities.
However, the solution isn’t just more data—it’s cleaner, more reliable data. And this is where the importance of having the right tech partner comes in. At Manolin, we help farms unlock the value in their data by offering the technology needed to transform unstructured, “messy” data into a valuable, structured asset.
By trusting tech partners with proven capabilities in data cleaning and self-healing technology, farms and suppliers can move beyond mistrust and confusion. They can rely on their data to make smarter, faster decisions—whether that’s tracking fish health with precision or evaluating product performance with confidence.
Real-World Applications: How Clean Data Unlocks Insights
Messy data can often feel like an inevitable reality. But with the right tools, it doesn’t have to be. Population tracing, for example, enables Manolin's data modeling to trace fish populations over time, understanding the full health journey of each group. But the power of this technology is only realized when paired with clean, structured data.
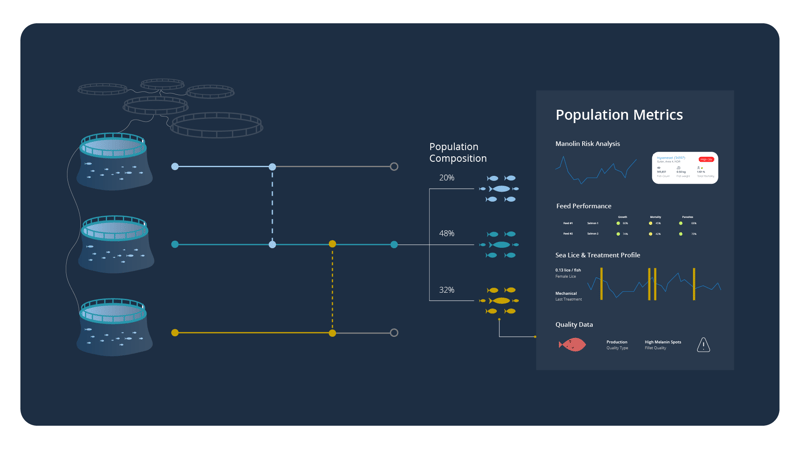
Imagine a scenario where multiple fish populations are moved between cages over a generation. The health and treatment records of these populations are scattered across various systems and documents. By employing self-healing data modules, those records can be automatically cleaned, optimized, and merged to reflect the most accurate picture of each population’s health.
For suppliers, clean data means they can evaluate their products with confidence. Without clean, structured data, it’s nearly impossible to measure the true performance of a treatment or product across different farms. But with enriched data, suppliers can pinpoint exactly how their products are impacting fish health and quality, and make data-driven adjustments proactively.
Messy Data Is Dead—It’s Time to Trust Your Data
The concept of messy data is dead. The truth is that all data has value—you just need the right tools and technology partners to help you uncover that value. With self-healing data modules, data cleaning technologies, and trusted tech partners like Manolin, farms and suppliers can take messy, unstructured data and transform it into an asset that drives smarter, faster decisions.
In today’s aquaculture industry, clean data isn’t a luxury—it’s a necessity. The future belongs to those who can trust their data and use it to unlock valuable insights. Now is the time to move beyond the “Garbage in, Garbage out” mentality and start trusting the power of your data.