One rainy February morning in Norway I woke up to an alert of a failed data pipeline. I jumped out of bed from the rush of adrenaline and logged onto our cloud provider’s platform to notice a cost increase of about $200 in a matter of days. Usually this kind of cost is no cause for concern but something seemed odd as I was unaware of any large data re-loads within our system.
I started digging, a pipeline responsible for our feature creation had been running for 2 days. Opening the logs revealed something that jolted me awake more than my typical 6 cups of coffee would. A log statement as follows:
“This may take a while…”, you got that right…

The Bottleneck No One Saw Coming
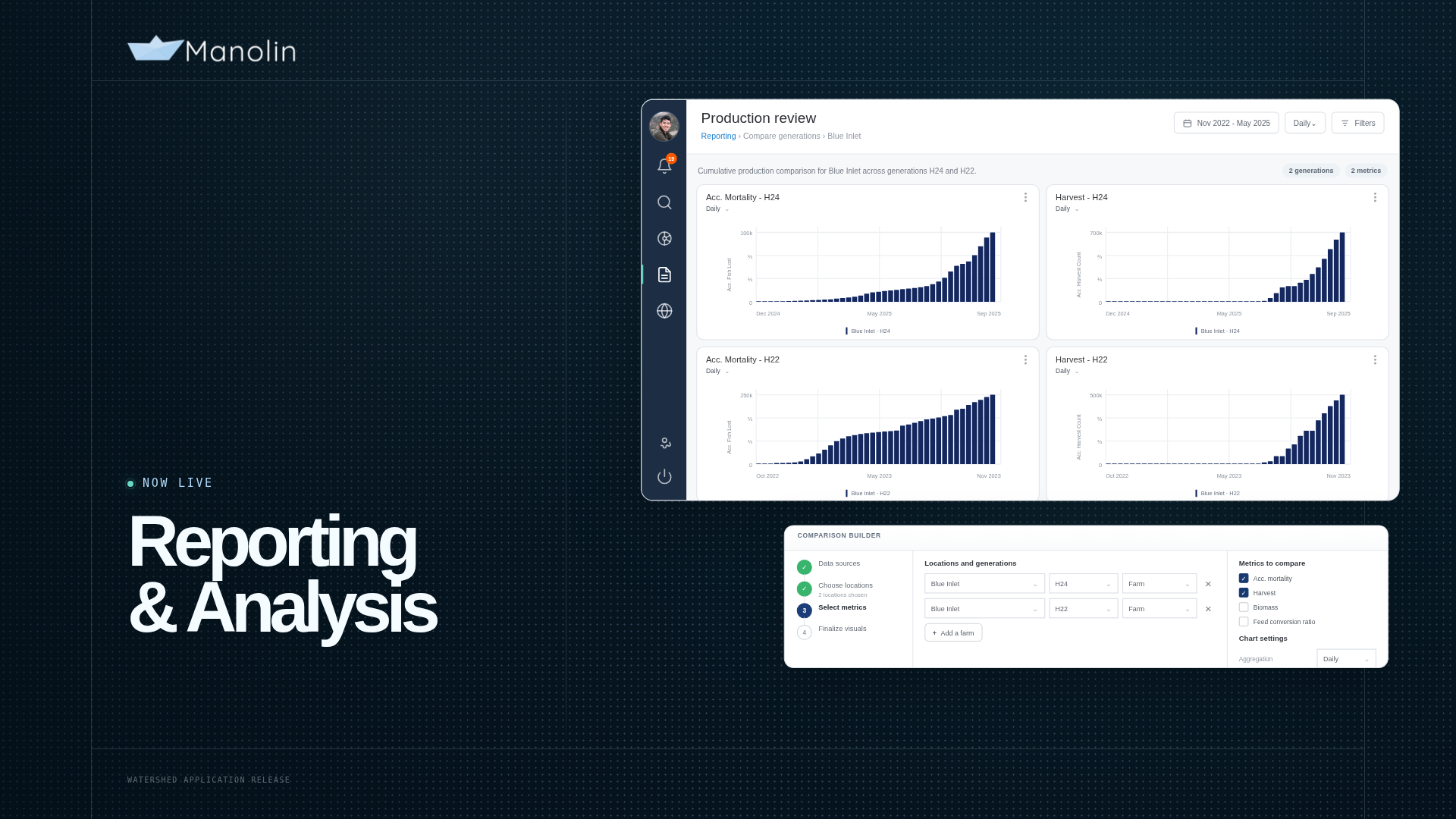
Our feature creation pipeline serves the purpose of tracing movements of fish between cages so we can understand the entire lifecycle of each fish and then create metrics such as growth, mortality, and feed rates on top of it. The movement tracing essentially works like this.
- Flag any record which has a change in biomass which likely stemmed from a movement event.
- For each flagged cage create the possible movements along a score on its validity. A parent cage can go to one or more children and vice versa. In technical terms this is called a “Many to Many” relationship.
- Create all possible combinations of the movements and then determine which is the most likely scenario based on a combined score.
The problem that arose is the number of movements grew to a size so large that with today’s computing power it would be physically impossible to compute all the combinations. In an effort to make this more relatable, Chat GPT 4.0 was trained on about 25,000 Nvidia A100 GPUs for around 100 days.
For this particular population trace it would take more GPUs than atoms in our universe and more time than the estimated existence of our universe.
And this is just 1 farm of the 100s that we have within our system.
To put it simply, even if Manolin had the resources to purchase ten quadrillion vigintillion to one-hundred thousand quadrillion vigintillion GPUs I would be long dead before the tracing completed. Suffice it to say we needed to come up with an alternative approach.
Why It Mattered - Downstream Impacts on Fish Health
Population tracing was created because old farm data didn’t record fish movements and new data either has errors or has no way of accessing that information because their record keeping system does not expose it for consumption by other machines.
If the engine stalls, farms lose visibility into the fish's history which powers the key contexts in our models used for planning of treatments, feeding, harvests and event product usages.
Tracing these movements isn’t a nice-to-have. It’s how we link performance, welfare outcomes, and treatment decisions to the fish that actually experienced them. Without this traceability, predictive insights get fuzzier and decisions carry more risk. It is the key difference between raw data and real intelligence.
Flipping the Script - A New Approach
In our previous version of population tracing we implemented a filtering function which removes any movements which were unlikely. This is where problem one arose. The movements that we had were all potentially valid and thus very few were actually filtered. The second issue was that in order to filter something you have to first create it. This meant that each of the 20.3 Nonillion movements took up a very tiny piece of our machine's finite memory, eventually consuming all of it. The system was trying to load the universe just to find a drop of water.
The fix? Reduce memory consumption and optimize the way we prune invalid combinations of fish movements.
Fixing memory consumption was quite trivial. We simply needed to only process a movement if it is valid and only score one at a time instead of processing and scoring all movements regardless of validity and then filtering after the creation. For the technical folks we utilized the above in combination with python generators to further reduce memory footprint.
With this change in place I re-ran some tests and reduced the time it takes to compute movements from infinity to about ~200ms. However the next step still ran for a seemingly endless amount of time which meant that the number of movement combinations was still too large to compute.
Diffusing a Ticking Time Bomb
The problem of combinatorial explosion is a well known concept in the fields of computer science and mathematics. Games like Sudoku, Chess, and Go suffer from the same symptom, although in their case it's a benefit. In ours it's a death sentence.

Example of what combinatorial explosion looks like.
Our attempt to solve this essentially had 3 new “rules” in our code.
- Any chain of combinations which don't have enough places left to fit the rest of the parents or children are stopped from going deeper in the combinatorial tree.
- Pruning is done on any chain of combinations which encounters a duplicate parent or child cage so we don’t continue traversing deeper into the tree.
- If a perfect combination is found where all transfer indicators such as biomass line up we implement early stopping to return that ideal solution and stop all other tree traversals.
With all that complete, time to test if our results work.

To my surprise, not only did we get the function complete, but we also cut the runtime from infinite to ~600 milliseconds!
Just like that we went from unusable to near instantaneous results and more importantly no more blind spots in historical risk or stalled future forecasts. As part of our testing we stress tested exceeding large transfers, things like 90 parents to 70 children. Even during the most extreme scenarios tracing is still able to complete within 10 seconds allowing Manolin to preserve visibility, audit history, and performance signals without any significant delay.
Scaling Intelligence, Not Just Infrastructure
Population tracing is one of the many things the Manolin engine does behind the scenes to power smarter aquaculture. But it’s also a reminder of the invisible complexity when it comes to making something “just work”.
When farmers use our platform to track treatment performance or plan harvests, they’re seeing the output of an unfathomable amount of operations which are pruned, optimized, and simplified to just the key actions that matter.
It’s why a farmer can ask:
- “Where should I be treating and what product should I use?”
- “Should I be harvesting a cage or letting the fish grow longer? What are my chances of mortalities occurring and hurting my bottom line?”
- “My fish behavior is unusual, what is the most likely cause? Should I be ordering PCR and Histology testing? How confident are we in this forecast?”
and get a clear answer with an action plan. Not another report, graph, or dashboard, but instead a decision.
What Happens When Complexity Disappears
It is great to see the Aquaculture industry’s desire to expand their sensor arrays and collect even more data. However, I feel the industry needs to be reminded that data is only a part of the equation.
When we talk about the Manolin engine, we’re not just talking about speed. We’re talking about resilience, the ability to scale as the industry scales. To surface patterns before they’re visible and have questions answered before they are asked.
Sometimes, that means rethinking how 20.3 Nonillion things get done. That’s what makes data intelligent. When all those individual data points from lab tests, management software, cameras, and farm sensors are reduced to a decision. An actionable insight where complexity disappears. More data points are only a benefit if we are utilizing the right system intelligence to extract the important insights.